Seismic
In Cognite Data Fusion (CDF), the Seismic resource supports managing and accessing seismic data volumes used by geologists, geophysicists, and other disciplines when planning and developing subsurface fields. As a component of the Cognite Subsurface resources, this will let you catalog and explore seismic data connected to well data, interpretations, and other relevant data.
Key terms for seismic services
This section introduces the key terms and elements that are the building blocks for the seismic services.
Coverage
Coverage is a polygon that represents the area covered by the actual traces in a file. It's different from the navigation polygon, which refers to the extent of the area covered by a ship during acquisition.
Cube
Cube is sometimes used as a synonym for volume or a 3D object representing a 2D array of traces. It refers to the volume of traces mapped to a rectangular area. In terms of seismic: A seismic cube is a 3D representation of a seismic volume. The data is sorted by inlines and crosslines (aka xlines) interpolated to create a 3D volume.
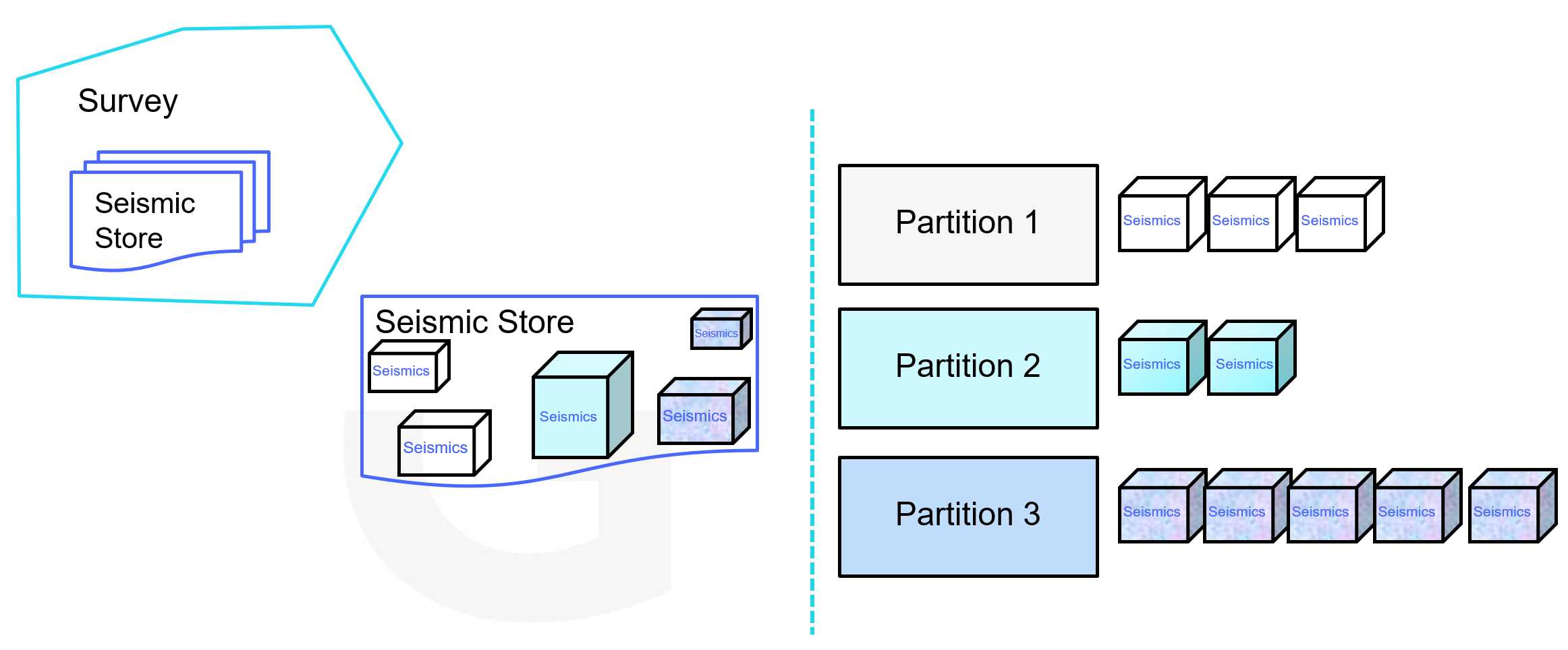
Partitions
A container/collection of data to be made accessible to a set of participants.
SEG-Y
A standard format for representing seismic data. It's a sequential file composed of:
- Text Header - a free form, human-readable header where users can add extra data about the file. It has a fixed-column layout.
- Binary Header - contains important values to process the file, such as sampling, trace length, and format codes.
- Traces - the actual data split in:
- Trace header - information for processing the trace data. It may override values in the binary header.
- Trace data - the trace values converted into float format after ingestion. Because SEG-Y is a format mainly developed for sequential recording in tapes, it's read sequentially, with information in the headers tied to its byte position in the file. Multiple objects can reference the same text header, for example, if a header isn't specified when creating a Seismic, it references the seismic store's header when retrieving headers.
Seismic
Seismic is a no-copy view into seismic stores. Once it has been defined, either via a polygon to "cut out" from the origin seismic store or via an explicit trace-by-trace mapping, you can't modify it. Seismics can be assigned to partitions, and you can restrict user access to particular partitions. Thus, they serve as the most granular unit of access control. Each seismic has one corresponding partition, and if a user is restricted to a particular partition, they will only be able to view the seismics assigned to the partition.
Seismic store
Represents a set of related traces and where to find them. Seismic stores are usually generated from an ingested file. Possible locations include Google BigTable, Google Cloud Storage, etc. The SeismicStore object is where we would manage the storage method of the underlying set of traces.
Storage tier
A single storage tier is a group of storage methods with similar access properties used when retrieving seismic data from an ingested file.
The available storage methods within a single storage tier are pre-configured on a per-tenant basis.
Storage tiers are in early access. The tier names, storage methods, and technologies used are subject to change as this feature is under development.
Survey
A survey refers to one event of acquisition of data on a particular area. In seismic data, one survey represents the acquisition of seismic reflection of a large 2D area. It has many files representing different processing states and attributes on top of the same original acquired data.
Trace
A trace is a collection of values representing the amplitude of a signal, ordered by time or depth, depending on the data type. A trace is the unit of seismic data and can be mapped to one point in 2D space, which can be defined either by its coordinates (x, y) or by its specific position in a seismic file in terms of (inline, crossline).
Volume
Volume is a matrix or 2D array of traces representing a 3D section of data. All the traces inside an arbitrary polygon on a surface define volume.
Seismic services data model
The illustration below shows a simplified data model for the seismic services:
The life of a seismic data set in CDF
Initially, your data lives in the cloud storage bucket, and CDF knows nothing about it.
To load the data into CDF, you first need to register the source data file in CDF to inform CDF about the location and format of the file. It's then ingested in CDF to build a representation of the dataset.
Once you have ingested the data set, it's represented as a seismic store, either based on Bigtable ("Tier 1") or Cloud Storage ("Tier 2"). The seismic store has all the traces in the source data set. You can query data in a seismic store for QA purposes.
To enable querying and processing parts of the trace data in a seismic store, you can create seismics, objects representing a view into the origin seismic store. This view can be either the complete data set or a subset/cutout depending on the line/bin numbers or a geographical region.
By default, data managers can access all seismics and seismic stores in a tenant. However, non-privileged users can be restricted to view only certain seismics by using partitions. Seismics are assigned to partitions on creation, and data managers grant users access to specific partitions. Users with partition-scoped access permissions can only see the seismics assigned to them and can't view seismic stores at all. However, they can access all the metadata and trace data associated with the subset of the seismic store they can view.
Deleting a seismic is a simple operation. Because seismics are views rather than copies, they're lightweight and can be deleted without touching the underlying data. Deleting a seismic store is more complicated. All seismics derived from that seismic store will also be deleted, and all references to the ingested file will be purged from the seismic service (e.g., Bigtable, Cloud Storage) it was held in.