Events
In Cognite Data Fusion, the event resource type stores complex information that happens over a period. Events have a start time and an end time and can be related to multiple assets. For example, Events API includes Alarms, Process Data, and Logs.
The startTime and endTime for the event's period are represented in Unix Epoch time in milliseconds. CDF doesn't support fractional milliseconds and doesn't count leap seconds. You can specify both the start and end times in the future, but the end timestamp must be greater than or equal to the start timestamp for the input to be valid.
To describe and classify events, you can add arbitrary string values for description, metadata, type, and subtype. All the data is stored in string format when you store event information in metadata.
Note: Use the Data Modelling service to store manually generated, schedulable activities with low volumes, such as maintenance schedules, work orders, or other appointment-type activities.
For more information about how to work with events, see Events API.
Events and Time Series data are high-volume data types that can record data in microsecond resolutions. Avoid using Events as a Time Series store, especially when the data flow is from a single instance of sensors (temperature, pressure, voltage), simulators, or state machines (on, off, disconnected). The Time Series API provides very low latency read and write performance and specialized filters and aggregations designed to analyze time series data.
Rate and Concurrency Limits
There are limits on the rate of requests (RPS) and the number of parallel requests. A request exceeding the limits will result in a 429 error response: Too Many Requests.
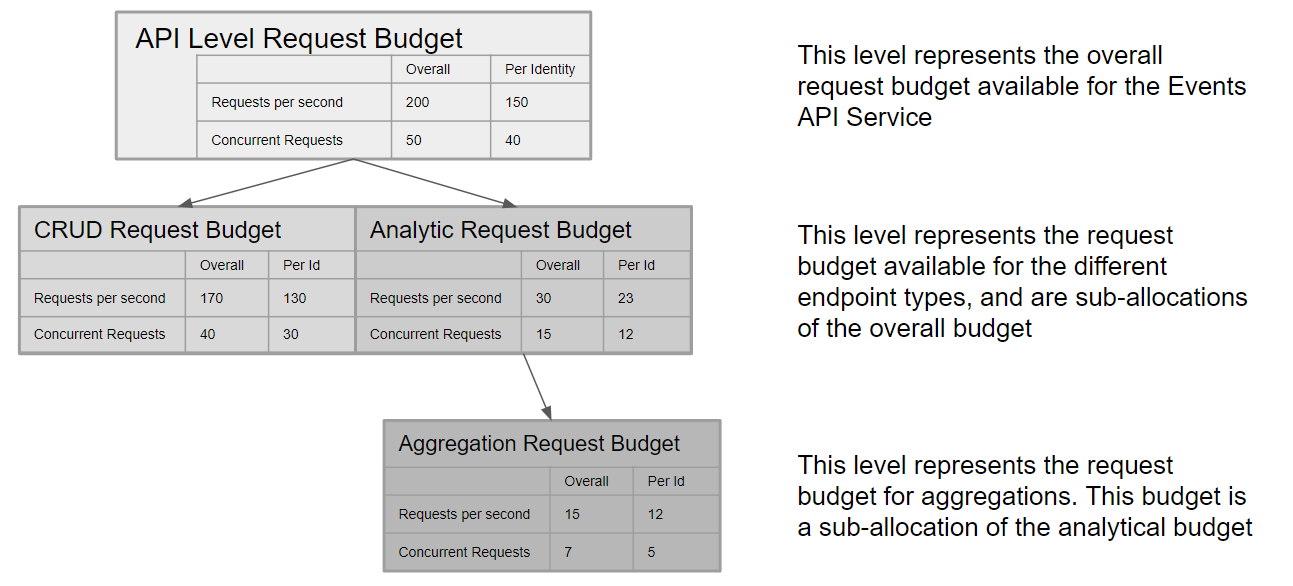
Define limits at both the API service and endpoint levels. Every request has a different budget due to the varying resource consumption. For example, there are two types of requests: CRUD (Create, Retrieve, Request ByIDs, Update, and Delete) and Analytical (List, Search, and Filter). CRUD requests are less resource-intensive than Analytical requests. Among all Analytical requests, Aggregates are the most resource-intensive, so they receive their request budget within the overall Analytical request budget.
The limits for the API service and its endpoints are shown in the diagram below. These limits are subject to change based on consumption patterns and resource availability over time. Changes to limits will be notified in the changelog.
Translate RPS to data speed
A single request can retrieve up to 1000 items, where 1 item is an event record. The top API service level has a maximum theoretical data speed of 200,000 items per second for all consumers and 150,000 for a single identity or client in a project.
Use of parallel retrieval
Parallel retrieval is a technique used to improve data retrieval performance in cases where due to query complexity, data retrieval speeds are lower than they would normally be with a fast, simple query. Use parallel retrieval to retrieve large data sets up to the capacity limits defined for an API service.
For example, the Events API request has the following limits:
- A single request can retrieve up to 1000 items.
- Up to 23 requests per second may be issued for an analytical query (per identity), such as when using /list or /filter API endpoints (see above diagram).
Resulting in:
- A theoretical maximum of 23,000 items read per second per identity.
Additionally, complex analytical queries may return data slower than the theoretical maximum. Typically, the more complex the query, the slower the data rate.
Resulting in:
- A single request taking longer than 1s to read or write 1000 items.
Therefore, for complex 'analytical' queries that return data slower than the theoretical maximum, the query should retrieve fewer items per request and more in parallel until the theoretical maximum performance of 23,000 items per second is reached.
Use parallel retrieval only when a single request flow provides data retrieval speeds significantly less than the theoretical maximum. The overall requests per second limit still apply regardless of the number of concurrent requests issued. For example, If a request returns data at 18,000 items per second, adding a second parallel request provides little benefit as only 5,000 more items can be returned before the budget limit is reached.